This lab showcases the ability to gather, analyze, and interpret publicly available data to uncover actionable insights. Leveraging OSINT techniques, explore digital footprints across social media, websites, public records, and metadata to simulate real-world reconnaissance scenarios. The project emphasizes ethical data collection, threat profiling, and vulnerability assessment, all without breaching privacy or security.
Cybrary is a well established and free IT training platform with several intuitive labs to explore
A paid subscription with more advanced labs is available as well outside the scope of this platform
Head to https://www.cybrary.it to create a free account for learning available on their platform
Head to OSINT to complete this training lab for yourself or perform on your homelab below
Quick Links:
Requirements:
• Windows PC w/ Internet Connection
• USB Flash Drive w/ at least 8GB Capacity
• Second PC with at least 2 GB of memory and 2 CPU cores
1. Create Kali Live USB
Kali Linux is an Open-Source Linux distribution which comes bundled with penetration testing tools
The OS is based on Debian and includes tools for network, social engineering and cracking attacks
You can use the operating system without having to install it onto your hard drive with a live usb
Download Kali Linux Live ISO: Kali Live Boot Official
Download Rufus Disk Imaging Software: Rufus Official
Insert USB Flash Drive, run rufus.exe, select target drive, select Kali Live Iso, start:

Remove USB Flash Drive and Insert into unused PC. Start PC and press hot boot key on startup:
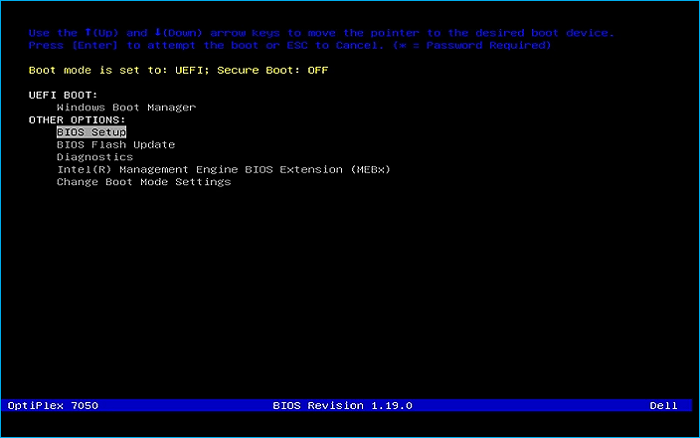
Select UEFI USB Flash Boot. Scroll to select Live System with USB Persistence to load the desktop:

This live system won't save anything on your PC's hard drive, and we will complete the lab here
2. Sync Time & Update Sources
Kali Live unfortunately often comes with a broken APT configuration out of the box, let's fix this
From the Kali Desktop Environment right click the background and left click Open Terminal Here:
Run the following command from the Kali Live Terminal to witness the broken APT configuration:
(kali@kali)-[~/Desktop]
$ sudo apt-get update
Resulting Output:

The key piece of information is the 'Not live until 2025-10-14T23:39:53Z' indicating time errors
This is caused because the Kali Live version does not have it's time zone synced out of the box
Run the following commands from the Kali Live Terminal to synchronize the systems time settings:
(kali@kali)-[~/Desktop]
$ sudo timedatectl set-ntp true
Run the following command from the Kali Live Terminal to test our solution to unsynchronized time:
(kali@kali)-[~/Desktop]
$ sudo apt-get update
Resulting Output:
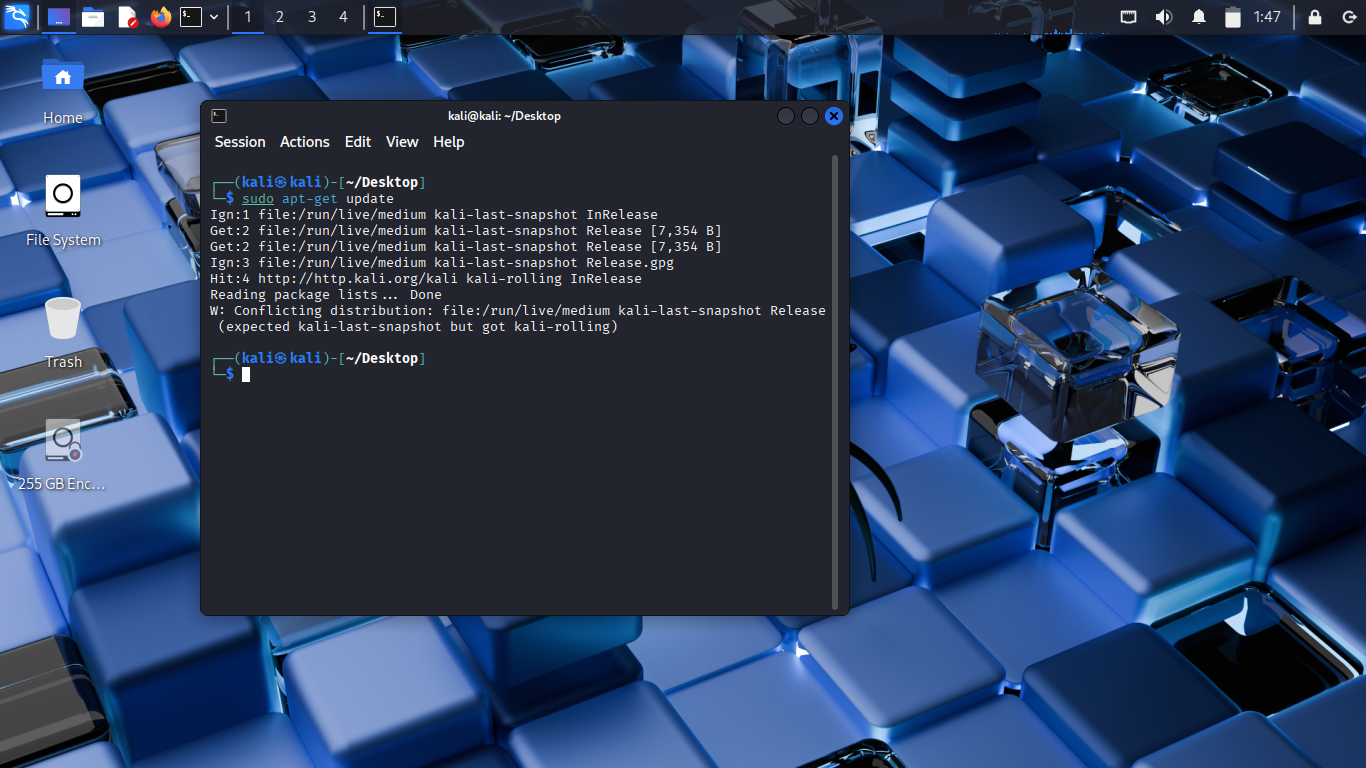
Our error message was reduced in size but not eliminated completely. We now have another error
The 'Conflicting Distribution' error is caused by an improperly formatted sources.list file
Run the following command from the Kali Live Terminal to edit the contents of our sources.list:
(kali@kali)-[~/Desktop]
$ sudo nano /etc/apt/sources.list
The Kali Live system by default includes the latest snapshot in a file rather than a proper link
Make changes to the first line of the file and add a second line so that sources.list reads as:
deb http://http.kali.org/kali kali-last-snapshot main contrib non-free non-free-firmware
deb-src http://http.kali.org/kali kali-last-snapshot main contrib non-free non-free-firmware
deb http://http.kali.org/kali kali-rolling main contrib non-free non-free-firmware
deb-src http://http.kali.org/kali kali-rolling main contrib non-free non-free-firmware
Save the changes in the nano text editor with CTRL+O and exit the program with CTRL+X
We now have a properly functioning APT package manager within the Kali Live system to utilize
3. OSINT Sources
Open-Source Intelligence or OSINT encompasses all of the information that is publicly accessible
This includes Websites, Print Media, and Locations. Weather paid or freely available for access
Reconnaissance refers to analyzing information to create actionable insights on a specific target
OSINT is a passive form of reconnaissance whereby information is gathered without direct contact
Open-Source Intelligence comes in many different forms but generally falls into two categories:
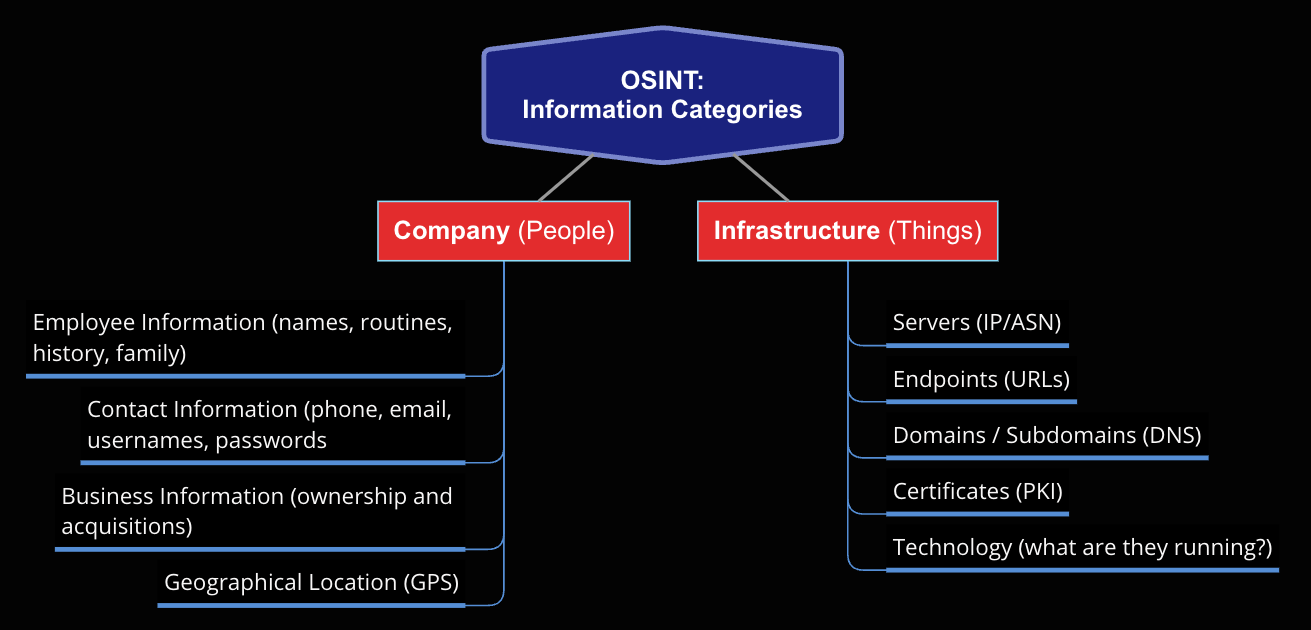
Open-Source Intelligence can be obtained from many different types of publicly available resources:
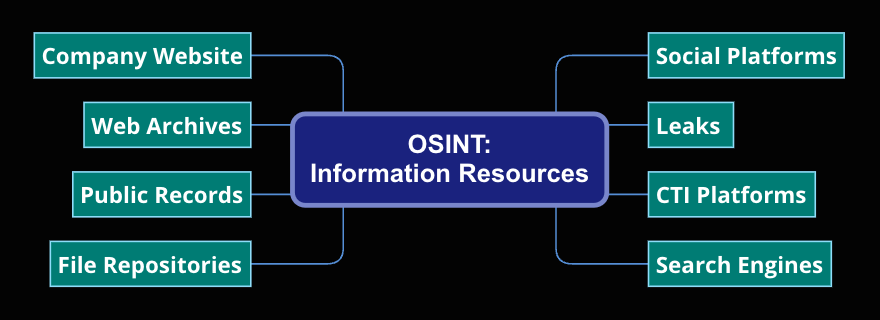
4. Websites
For this lab our target will be a cybersecurity company called Rekt Systems with a public domain
We start by looking for surface level information to begin to build a framework around our target
Once we have some basic identifiers we can properly assess and correlate information we will find
Head to your browser and enter the given domain rekt.systems into the URL address bar:
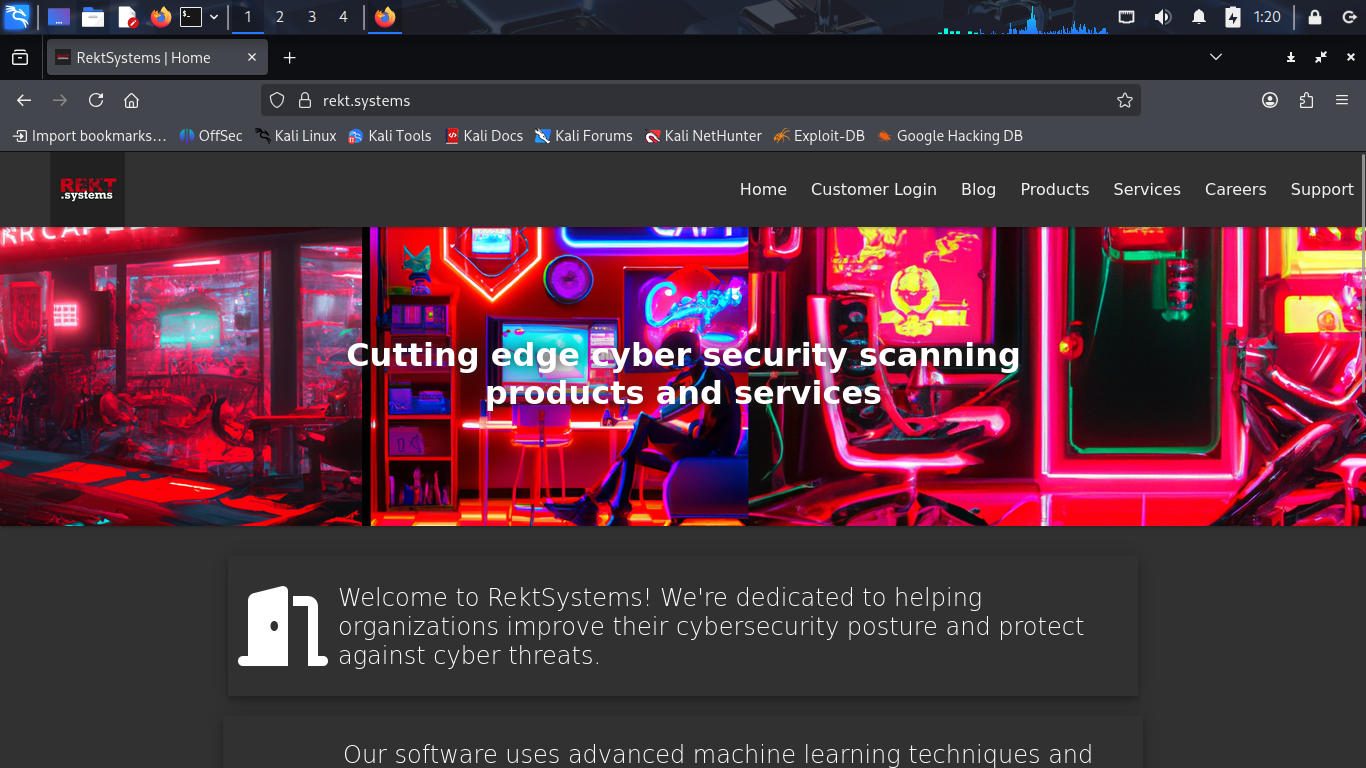
Let's explore the pages HTML Sitemap - The collective clickable links on the website accessible
Take note of any subdomains you can find and any indication of the stack or technology types used
Upon exploring each of the navigable links from the homepage we find a subdomain as login.rekt.systems:
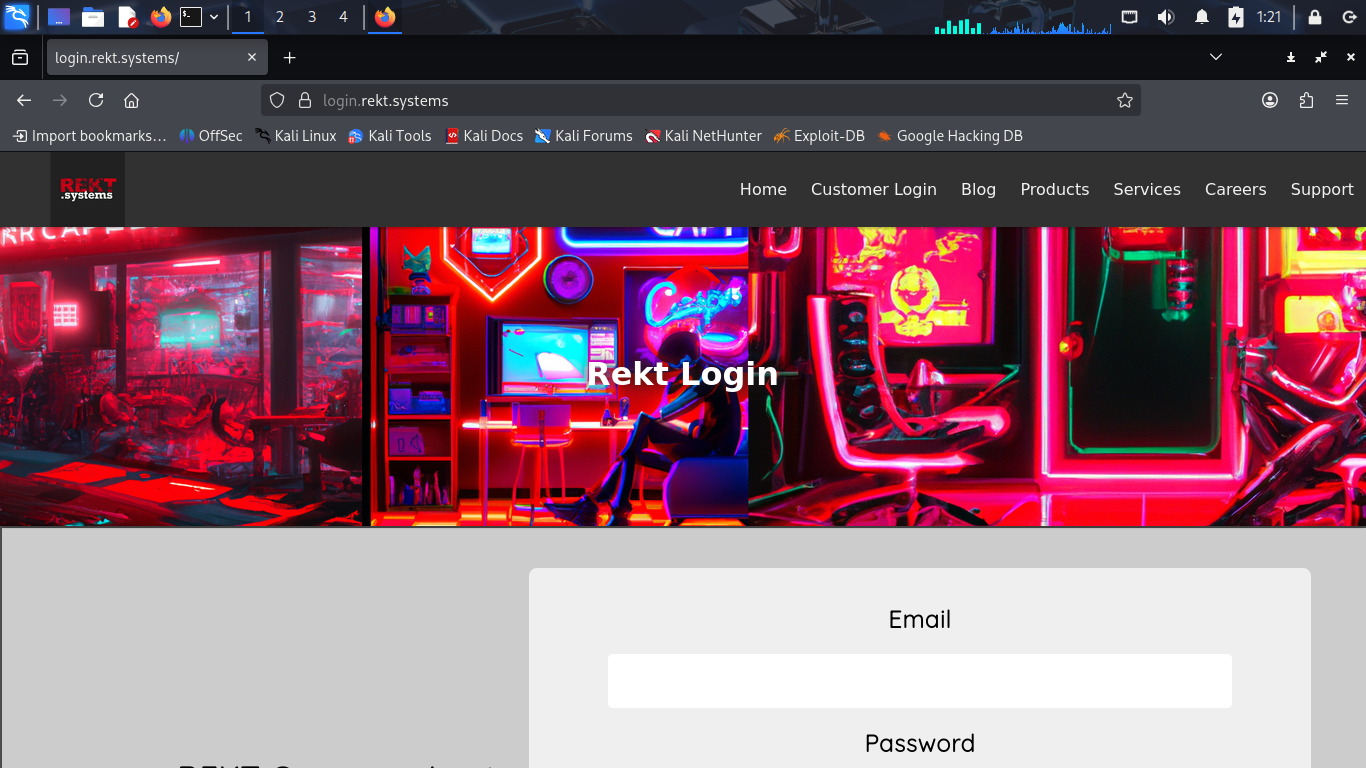
Let's head to the Careers page to search for information regarding their specific technology stack:
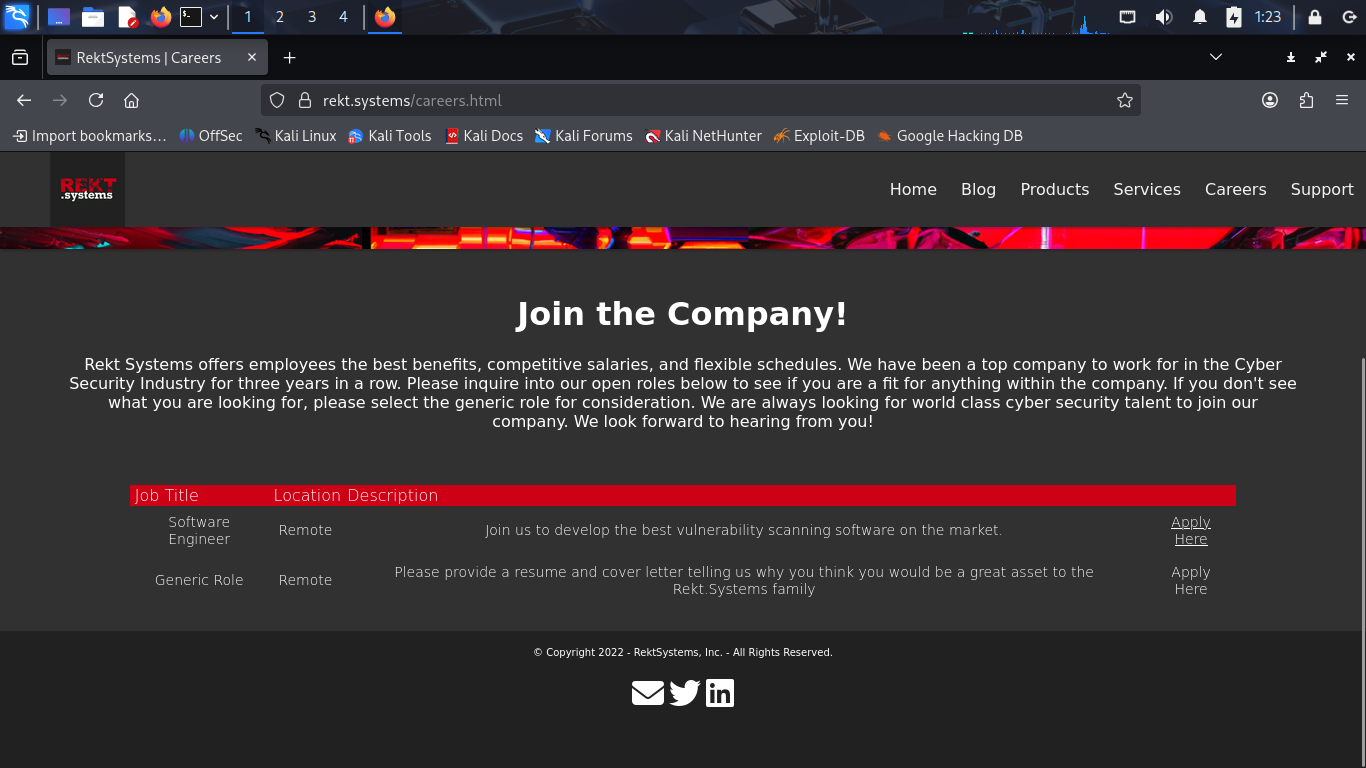
The job description for a Software Engineer role is very likely to contain experience qualifications
From here click on the "Apply Here" hyperlink located on the Careers page to search for this info:
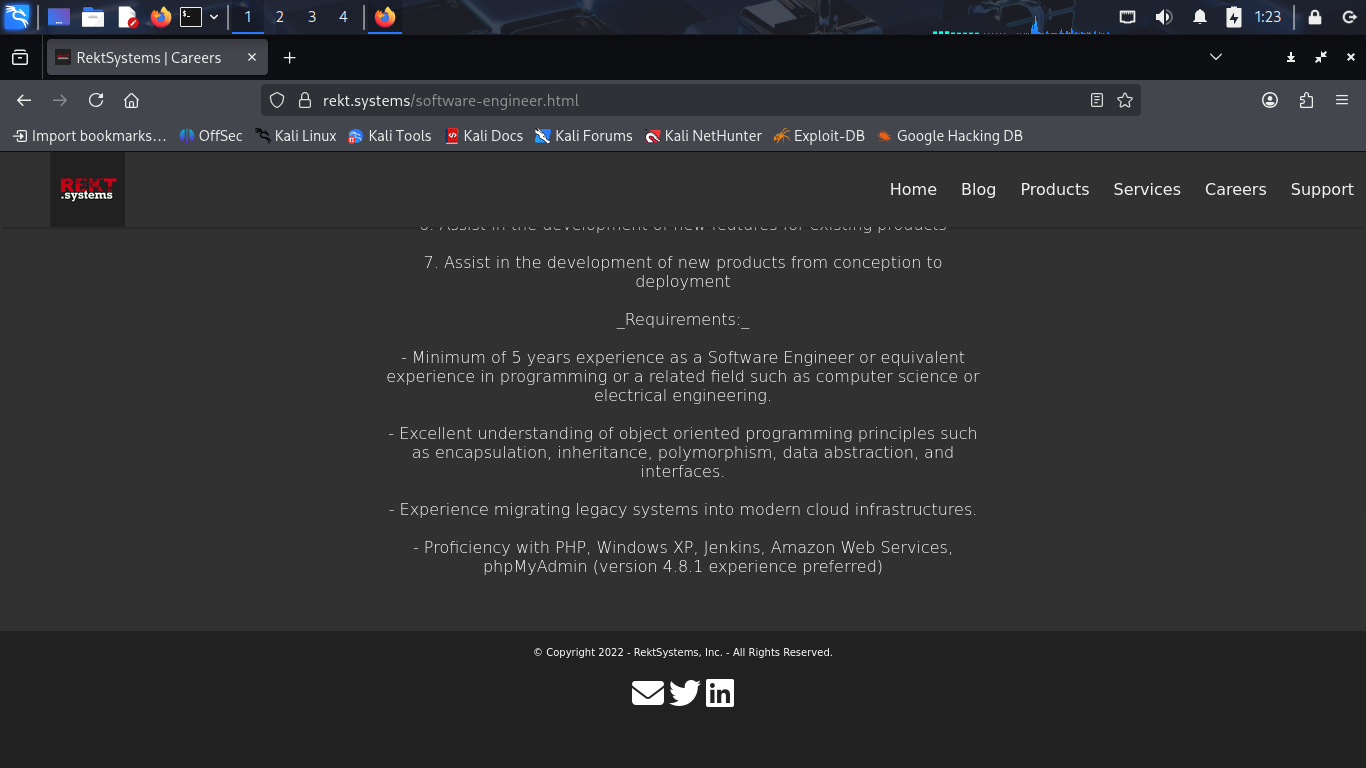
Here we can see the full job description for the Software Developer role including technology stack
This tells us what systems are used within the environment and what types of software run on them
Take note of the line listing phpMyAdmin version 4.8.1. Specific versions are useful for exploiting
Python is a multi purpose general programming and scripting language which includes many modules
The BrowserHistory module can be used to export web browser history into usable CSV text files
This is very useful for reconnaissance activities involving websites to map the HTML sitemaps
Here we will walk through the process of installing this tool and starting the service it uses
Run the following command from the Kali Live Terminal to update and upgrade existing packages:
(kali@kali)-[~/Desktop]
$ sudo apt-get update && sudo apt-get upgrade -y
This may take some time to fully upgrade each package, you will be presented with prompts as well
When presented with the Dumpcap and Wireshark prompt press Enter to select the given 'NO' option:
PIP is the official package manager for Python, which streamlines installation process for modules
Run the following command from the Kali Live Terminal to install the Python PIP package manager:
(kali@kali)-[~/Desktop]
$ sudo apt-get install python3-pip
Python will only install modules from the supported environment, in this case the Kali Linux Repo
In order for us to install the browserhistory module we must do so in a virtualized environment
Run the following command from the Kali Live Terminal to install the pipx environment extension:
(kali@kali)-[~/Desktop]
$ sudo apt-get install pipx
The pip command can be used within the terminal to easily install modules and libraries supported
Run the following command from the Kali Live Terminal to install the browserhistory module with pip:
(kali@kali)-[~/Desktop]
$ pipx install browser-history
We will now utilize the previously installed browser-history to export a CSV file of the sitemap
Run the following commands from the Kali Live Terminal to capture and export the browser history:
(kali@kali)-[~/Desktop]
$ browser-history -b Firefox -o browserhistory.csv
Let's check that the operation was successful by using the ls command from the Kali Live Terminal:
(kali@kali)-[~/Desktop]
$ ls
Resulting Output:
browserhistory.csv Documents Music Public Videos
Desktop Downloads Pictures Templates
Success, now run the following command from the Kali Live Terminal to view the contents of our file:
(kali@kali)-[~/Desktop]
$ cat browserhistory.csv
Resulting Output:
2025-10-18 01:57:55+00:00,https://rekt.systems/index.html,RektSystems | Home
2025-10-18 01:58:24+00:00,https://rekt.systems/blog.html,RektSystems | Blog
2025-10-18 01:58:29+00:00,https://rekt.systems/blog2.html,RektSystems | Blog
2025-10-18 01:58:35+00:00,https://rekt.systems/blog3.html,RektSystems | Blog
2025-10-18 01:58:41+00:00,https://rekt.systems/blog4.html,RektSystems | Blog
2025-10-18 01:58:48+00:00,https://rekt.systems/products.html,RektSystems | Products
2025-10-18 01:58:56+00:00,https://rekt.systems/services.html,RektSystems | Services
2025-10-18 01:59:01+00:00,https://rekt.systems/careers.html,RektSystems | Careers
2025-10-18 01:59:05+00:00,https://rekt.systems/software-engineer.html,RektSystems | Careers
2025-10-18 01:59:07+00:00,https://rekt.systems/support.html,RektSystems | Support
2025-10-18 02:15:00+00:00,https://login.rekt.systems/login.html,RektSystems | Login
Now we have a solid foundation for the companies website including all accessible parts of the sitemap
For us to actual make use of this information we need to separate the URLs fro the other information
Run the following command from the Kali Live Terminal to search for URLs and send them to a new file:
(kali@kali)-[~/Desktop]
$ grep -oP 'https?://[^ ]+\.html\b' browserhistory.csv | sort -u > url.lst
This will not only take out the url specifically but also ensure there are no duplicate url entries
Use the ls and cat command from the Kali Live Terminal to view the contents of our new file:
(kali@kali)-[~/Desktop]
$ cat url.lst
Resulting Output:
https://rekt,systems/index.html
https://rekt.systems/blog.html
https://rekt.systems/blog2.html
https://rekt.systems/blog3.html
https://rekt.systems/blog4.html
https://rekt.systems/products.html
https://rekt.systems/services.html
https://rekt.systems/careers.html
https://rekt.systems/software-engineering.html
https://rekt.systems/support.html
https://login.rekt.systems/login.html
This is a success, we have a list of pages on the target sites we can use to perform potential attacks
Websites often contain a combination of HTML, CSS and Javascript code to serve content dynamically
There is a ton of useful information we can gain about the target by viewing their sites source code
We can use a command line tool called getJS to extract the Javascript source code from the web pages
Run the following command from the Kali Live Terminal to install the go package manager used by getJS:
(kali@kali)-[~/Desktop]
$ sudo apt-get install golang
Run the following command from the Kali Live Terminal to install the getJS command with go:
(kali@kali)-[~/Desktop]
$ go install github.com/003random/getJS/v2@latest
Now the getJS packages are installed onto the system in go/bin/getJS but we must move them to $PATH
Run the following command from the Kali Live terminal to enable the getJS command to be used in the cli:
(kali@kali)-[~/Desktop]
$ sudo cp go/bin/getJS /usr/bin
Run the following command from the Kali Live Terminal to extract all the associated javascript files:
(kali@kali)-[~/Desktop]
$ getJS --input url.lst --complete | xargs wget
Resulting Output:
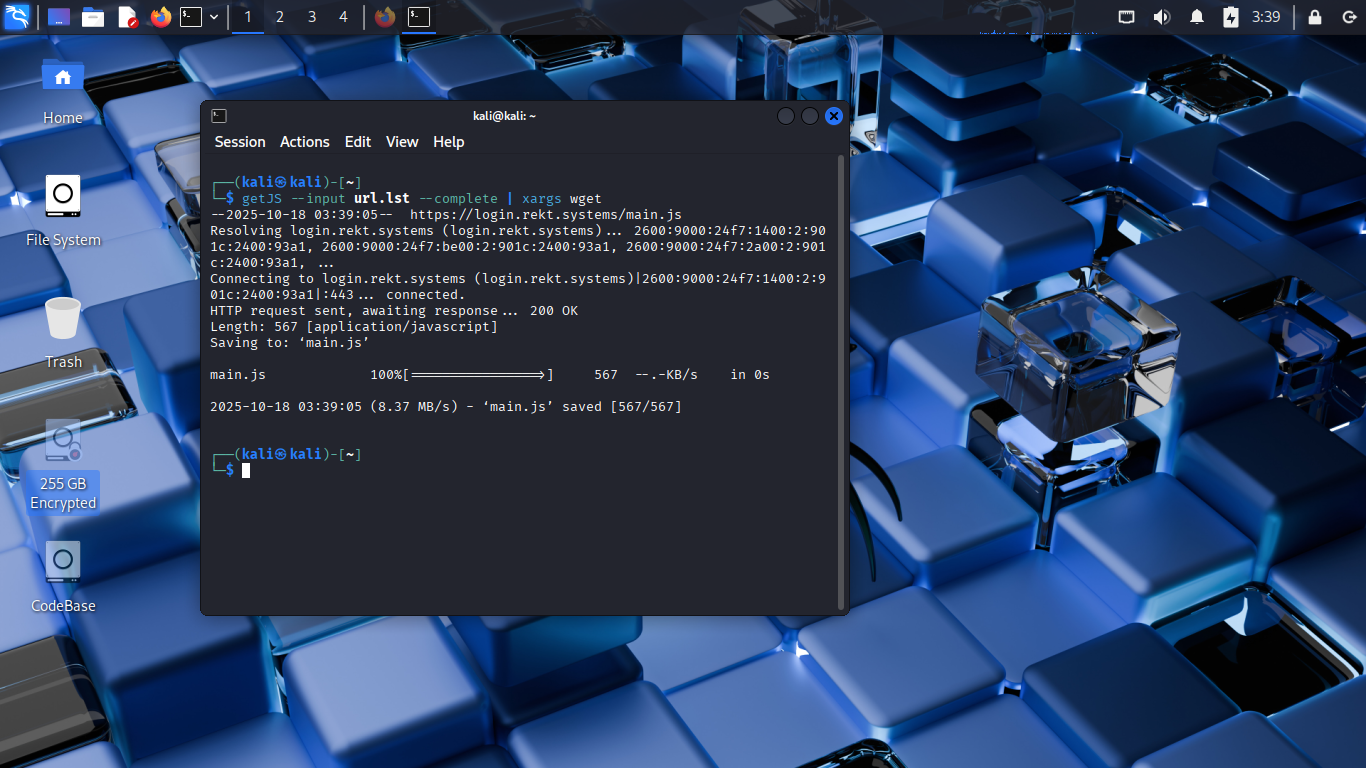
We have received a hit on the login.rekt.systems subdomain for a referenced javascript file in the code
Run the following commands from the Kali Live Terminal to extract any urls within the javascript file:
(kali@kali)-[~/Desktop]
$ grep -Eo 'https?://[a-zA-Z0-9./?=_-]*' main.js | sort -u >> url.lst
Run the following command from the Kali Live Terminal to check our list for any new entries:
(kali@kali)-[~/Desktop]
$ cat url.lst
Resulting Output:
https://rekt,systems/index.html
https://rekt.systems/blog.html
https://rekt.systems/blog2.html
https://rekt.systems/blog3.html
https://rekt.systems/blog4.html
https://rekt.systems/products.html
https://rekt.systems/services.html
https://rekt.systems/careers.html
https://rekt.systems/software-engineering.html
https://rekt.systems/support.html
https://login.rekt.systems/login.html
https://api.rekt.systems/get/user
We have located a new 'api' subdomain for our target. Let's switch things up and view from another angle
5. Search Engines
Search engines are one of the most powerful tools available for Open Source Intelligence Reconnaissance
They organize publicly available web servers which include content the user is searching for on pages
However that is not the only way they can sort web servers, engines also include many search operators:
• site:example.com - limit results to any ending in example.com
• inurl:term - limit results to URLs containing term
• intitle:term - restrict results to page titles containing term
• intext:term - restrict results to any page text containing term
• filetype:pdf - restrict results to PDF files
• ext:pdf - restrict results to files ending in .pdf
You can use these more advanced operators to careful tailor your search results and find information
The use of these operators in reconnaissance is known as 'Search Engine Hacking' and is very powerful
Head by to Firefox and head to IntelTechniques which provides useful tools for OSINT reconnaissance:
From the Intel Techniques website navigate to Tools > Search Engines, allowing us to use many engines
In the text box next to populate all type in 'site:rekt.systems filetype:xml' and click populate all:
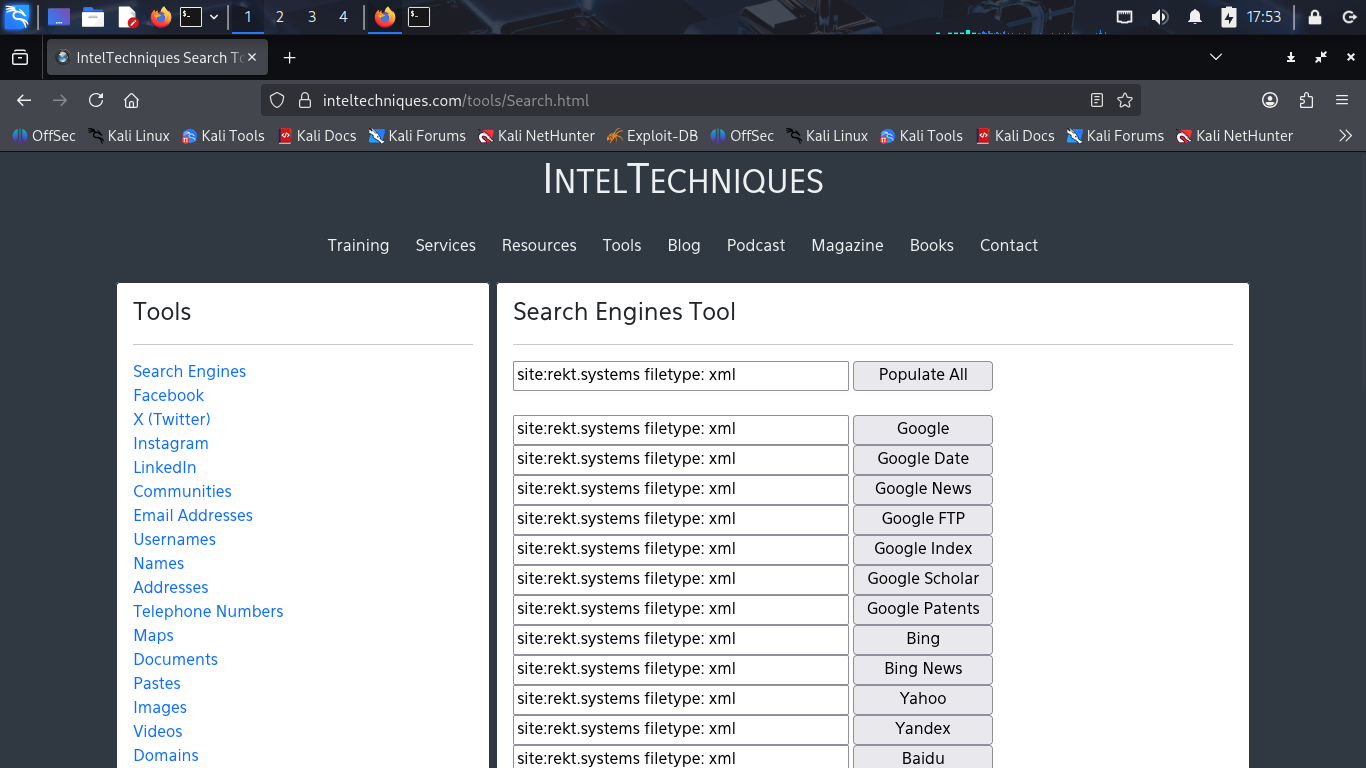
Click on the 'Google' button and navigate to the only result to view the websites XML sitemap file:
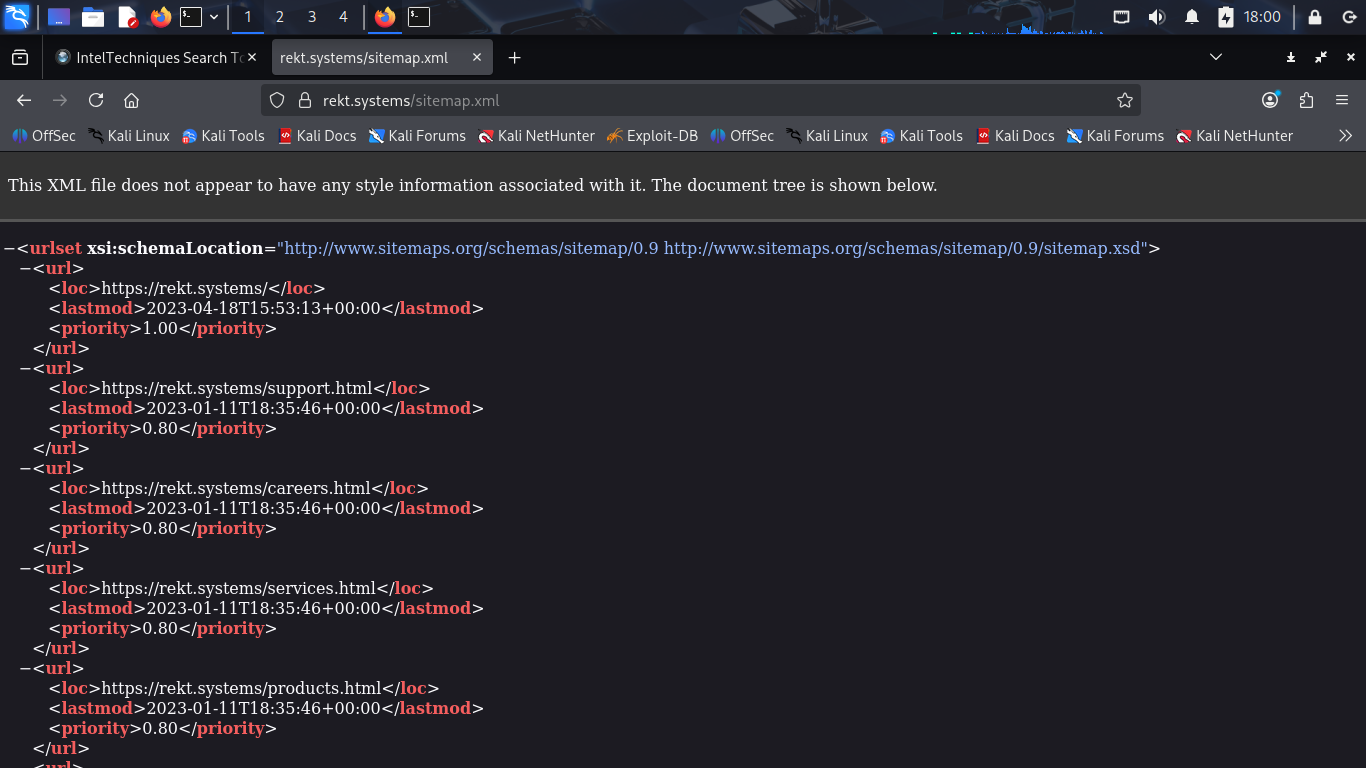
Look through the XML sitemap page for any links we missed in our website reconnaissance. Notice a PDF
Files are a great source of Open Source Intelligence as they may contain metadata about the systems:
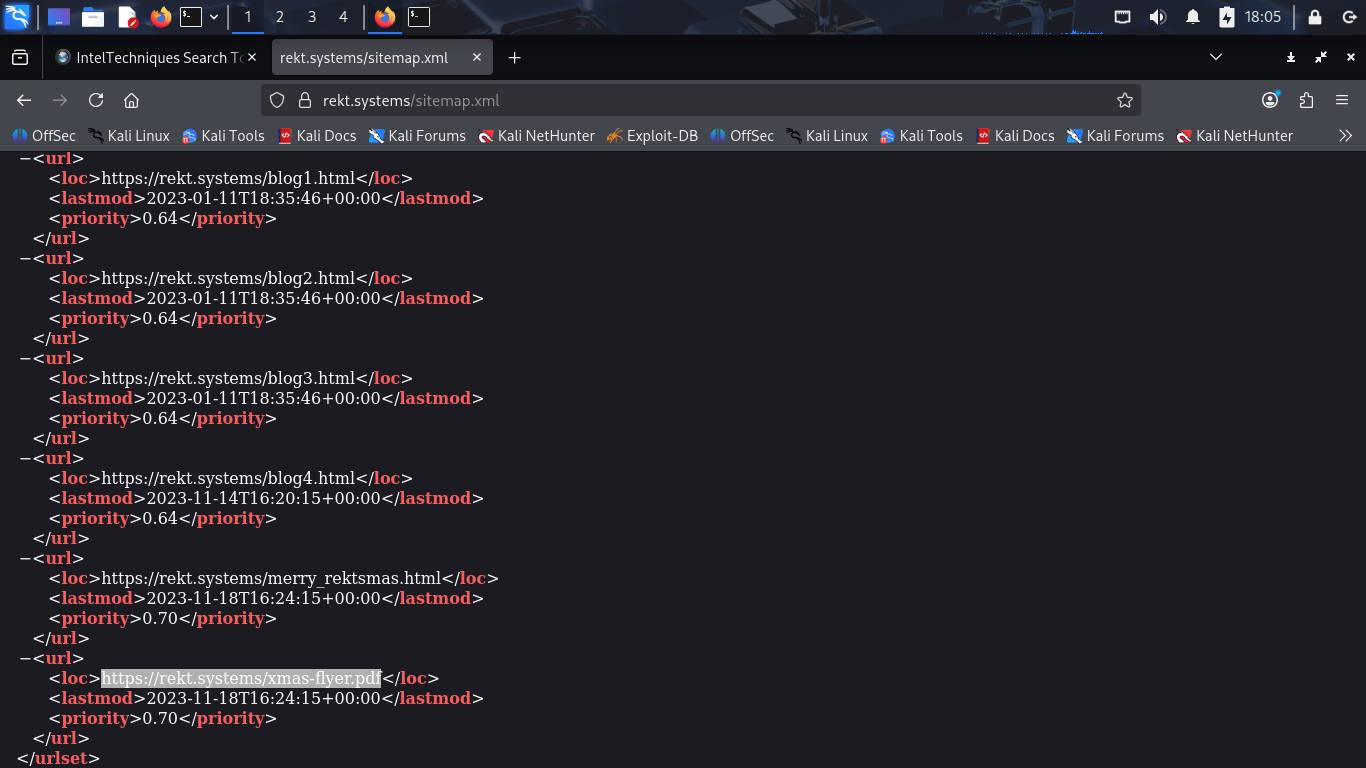
Let's download this file and see what new information about the target we can gain from examining it
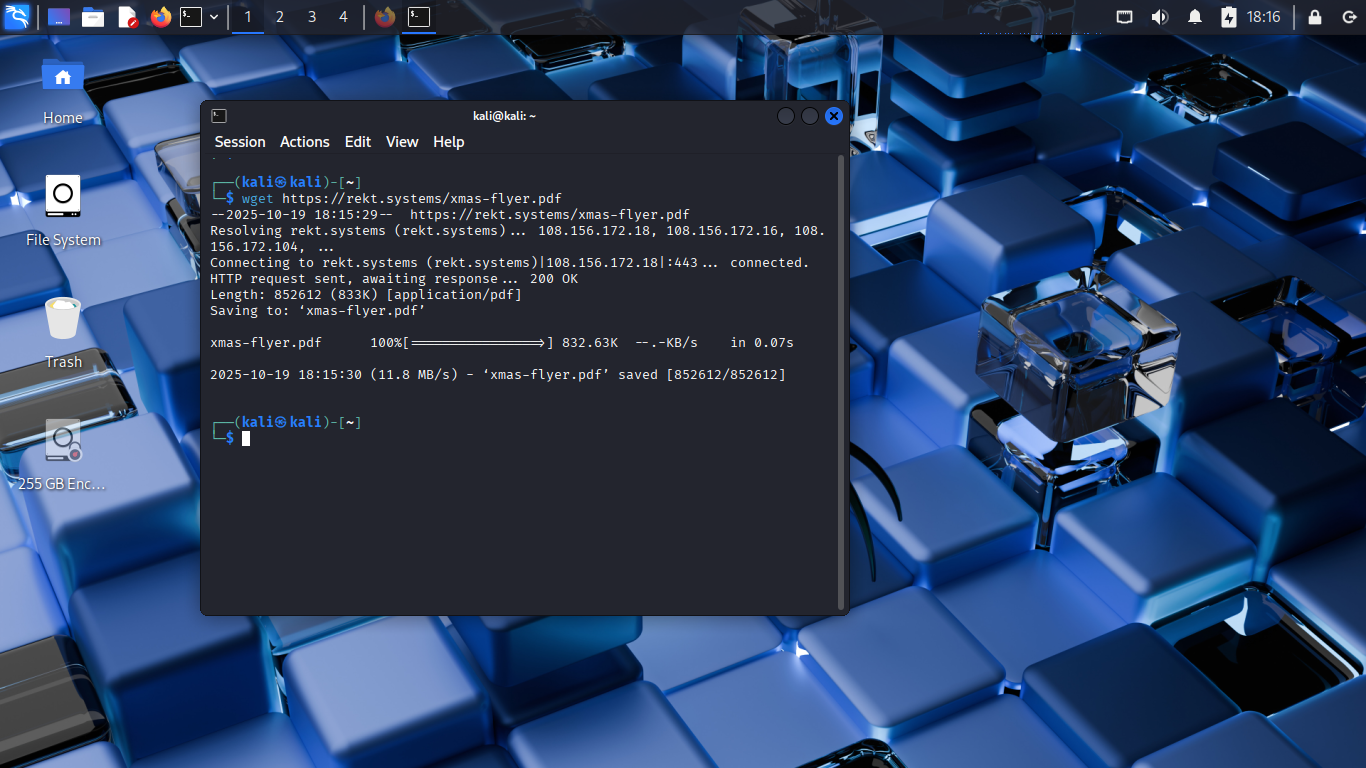
Run the following command from the Kali Live Terminal to download our new file from rekt.systems:
(kali@kali)-[~/Desktop]
$ wget https://rekt.systems/xmas-flyer.pdf
Resulting Output:
Kali Linux comes bundled with exiftool which is a command line utility which can print file metadata
Run the following command from the Kali Live Terminal to extract the metadata from our downloaded PDF:
(kali@kali)-[~/Desktop]
$ exiftool xmas-flyer.pdf
Many pieces of information are displayed from this commands output. Most useful to take note of:
• Author: DKinney
• Producer: Xerox AltaLink C8055
Let's do a quick google search to look for vulnerabilities in the discovered printing device used
We can easily find CVE-2019-10881 for the device which we could save to use in the exploitation phase
6. Public Records
Another great source for intelligence, public records are accessible to anyone and can be used here
Public Records are information which much be made publicly accessible for different legal purposes
For example the owner of a domain must be publicly available in case they try to host illegal content
From the Firefox Web Browser head to WHOXY and search for rekt.systems to reveal ownership information:

The client's privacy settings prevent us from seeing any contact information, but we can other info:
• Domain Registrar
• Country Code
• Name Servers
Next we will take a look at the SSL/TLS certificates that have been issued for this domain by CA's
Certificates are used to prove the servers identity and establish an encrypted channel for data
Certificates are captured in a public Certificate Transparency Log for all associated subdomains
Viewing this record can provides us with a convenient method for discovering additional subdomains
Run the following commands from the Kali Live Terminal to install the ctfr command line tool:
(kali@kali)-[~/Desktop]
$ git clone https://github.com/UnaPibaGeek/ctfr.git
(kali@kali)-[~/Desktop]
$ cd ctfr
Run the following commands from the Kali Live Terminal to enumerate the subdomains with ctfr.py:
(kali@kali)-[~/ctfr]
$ python3 ctfr.py -d rekt.systems -o ~/subdomains.txt
(kali@kali)-[~/ctfr]
$ cd ~
Use the cat command from the Kali Live Terminal to view subdomains we discovered certificates for:
(kali@kali)-[~/Desktop]
$ cat subdomains.txt
Resulting Output:
*.rekt.systems
rekt.systems
jira.rekt.systems
login.rekt.systems
vpn.rekt.systems
Keep in mind that these are subdomains with certificates, they may not actually resolve to anything
There could also be additional subdomains which resolve but do not carry any active certificates
7. CTI Platforms & Web Archives
Web Archives are historical databases documenting the internet and websites as they were over time
These can be used to see previously associated pages for our target even if they no longer exist
We will be using the command line tool GAU (Get All URLs) to probe multiple Web Archives for info
Run the following command from the Kali Live Terminal to install GAU with the go package manager:
(kali@kali)-[~/Desktop]
$ go install github.com/lc/gau/v2/cmd/gau@latest
Now the gau packages are installed onto the system in go/bin/gau but we must move them to $PATH
Run the following command from the Kali Live terminal to enable the gau command to be used in the cli:
(kali@kali)-[~/Desktop]
$ sudo cp go/bin/gau /usr/bin
Run the following command from the Kali Live Terminal to probe multiple Web Archives for URLs:
(kali@kali)-[~/Desktop]
$ gau rekt.systems
Resulting Output:
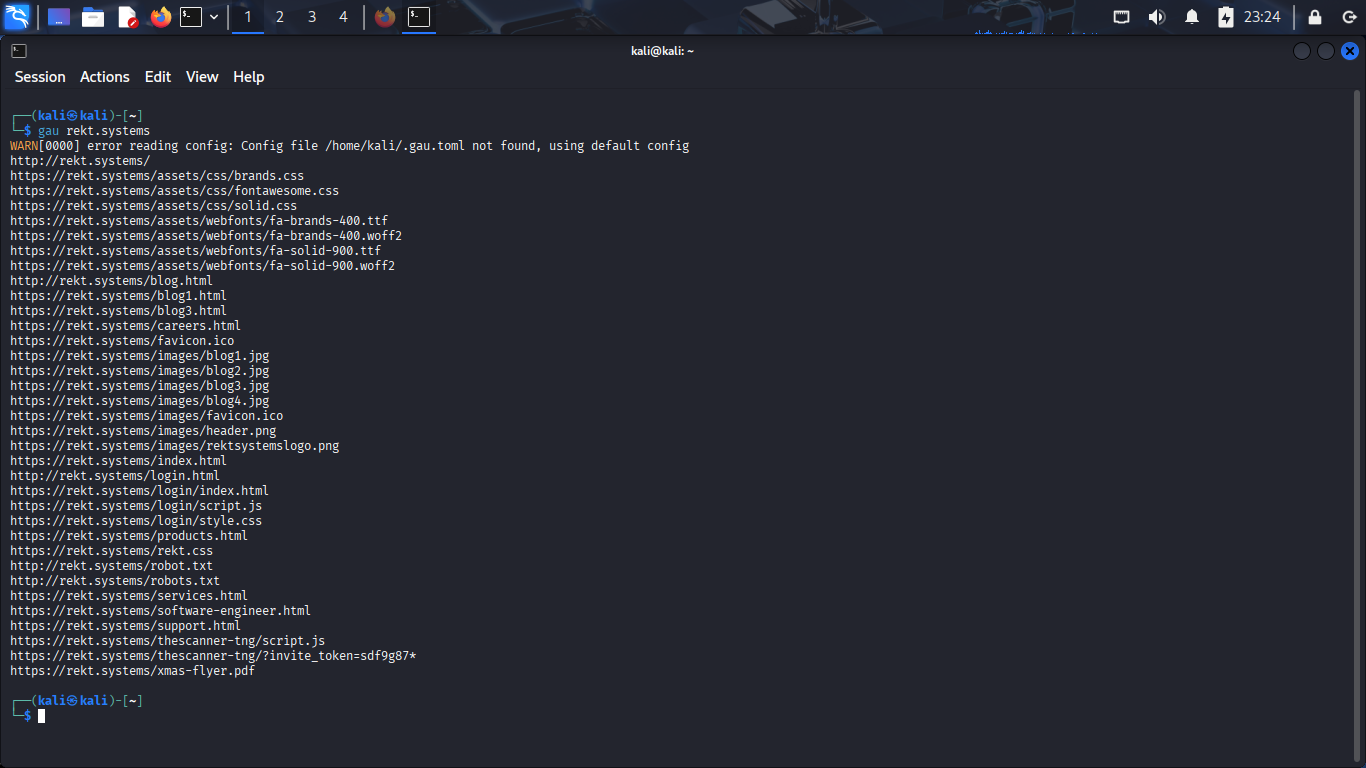
Bingo, now we have a ton of files to work from. Take note of the invite_token session key URL
We can attempt to use this session key to hijack the session and impersonate a legitimate user
From the Kali Live Terminal, right click the link with invite_token and hit the open link option:
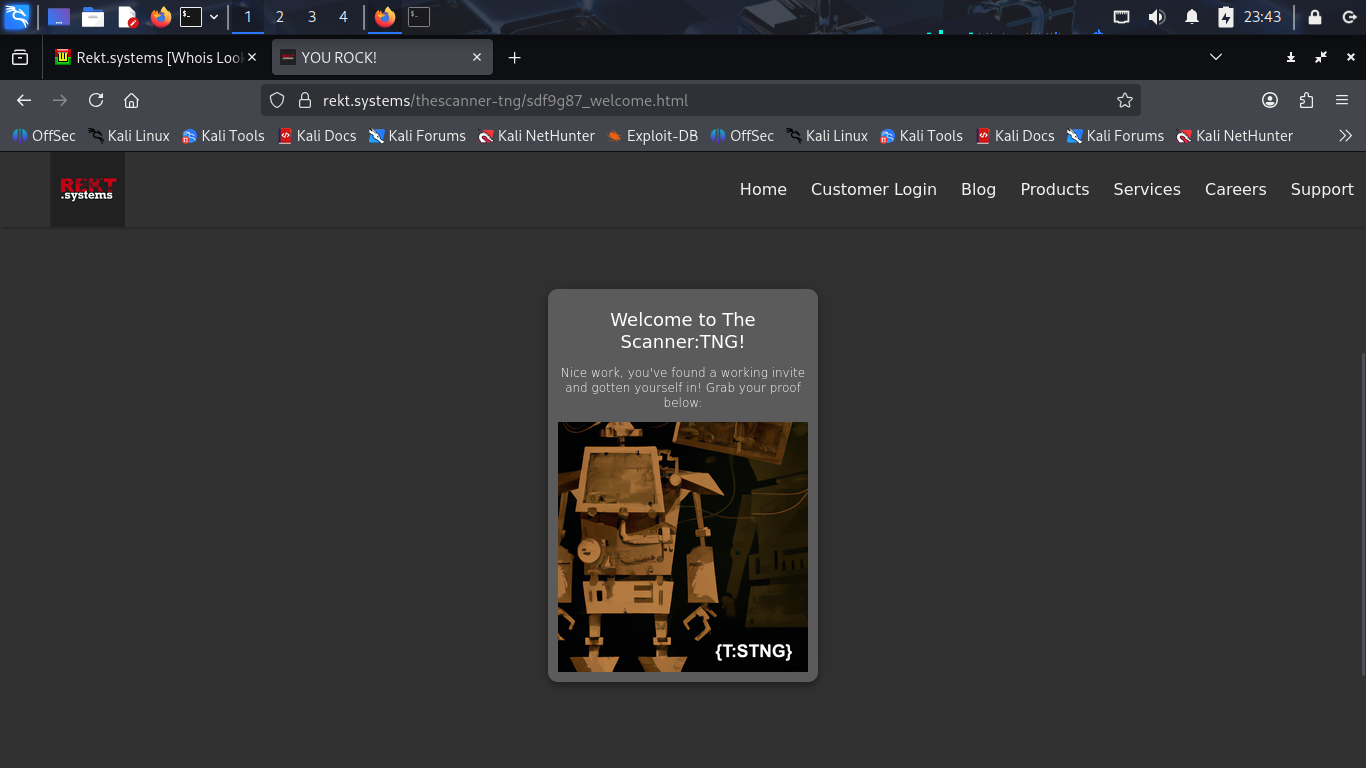
Congratulations, you have successfully performed a session hijacking attack during reconnaissance
8. Social Platforms
Social Media Platforms can be used to gather open source intelligence on the people with our target
The term 'Lurking' is a good summary, viewing and searching for peoples profiles without interacting
LinkedIn is a social platform used for work and professional related networking and public sharing
Head to Firefox and type in "site:linkedin.com intext:rektsystems" to search linkedin for our target:

Doug Kinney seems very similar to the DKINNEY author listed for the xmas PDF file discovered before
Click on the profile link for the companies CEO and likely PDF file author to discover his email:
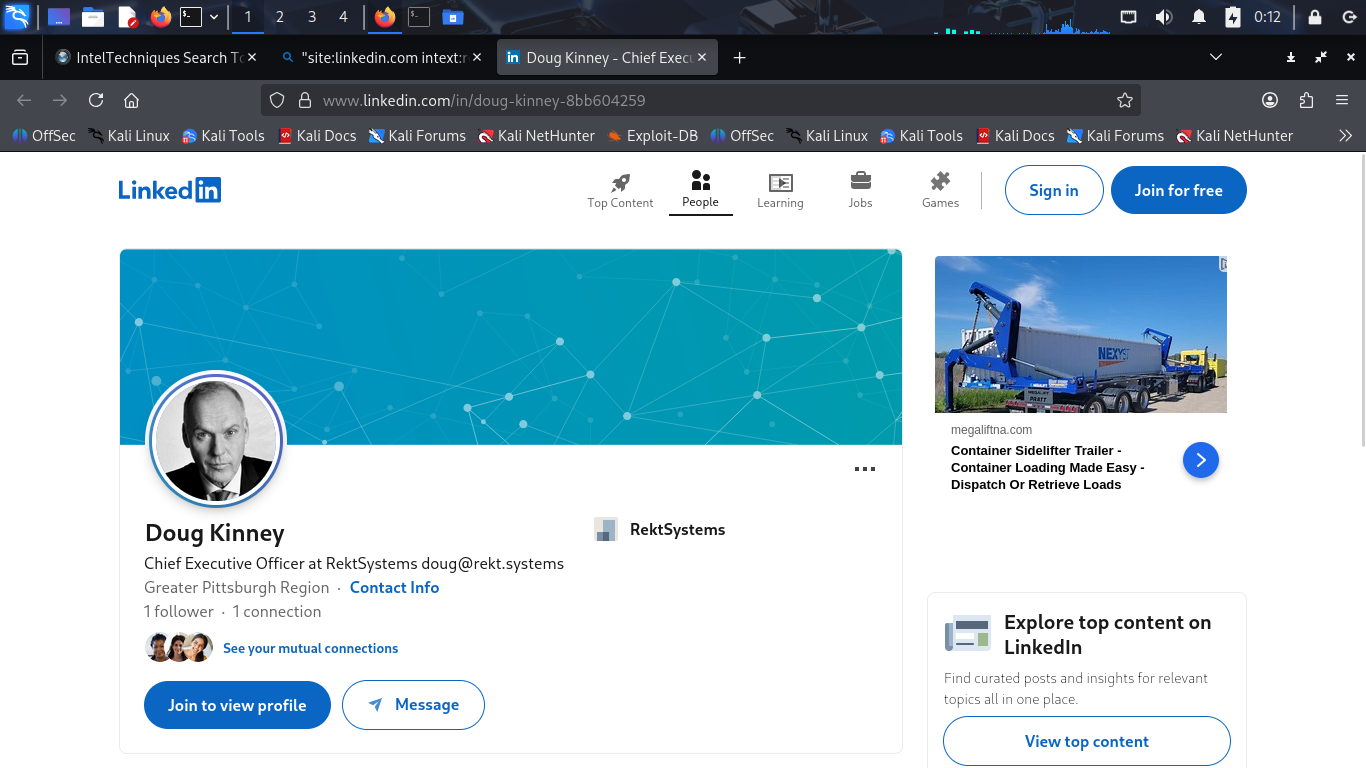
Great job, without leaving a single trace on any systems, we've discovered the CEO's email address
This concludes our lab on Open Source Intelligence Reconnaissance, you now have the tools necessary
Check back for future labs where we go beyond this and enter the exploitation and documentation phases